By Pedro Pinto
1 Overview
Latency remains a key concern in options trading. In today's increasingly competitive markets the penalty for slowness is steep and traders whose systems are not designed from the ground up with low latency in mind soon find themselves being picked off by faster competitors. At BTS we understand better than most the importance of speed. As former traders ourselves we have experienced first hand the impact of latency on the bottom line and for this reason we have designed our electronic trading systems from the ground up with speed as a primary concern. In this article we present the results of this effort by benchmarking our Options Quoter, available as part of the BTS Edge System. We begin by describing our benchmark methodology: what Hardware was used, how the BTS Edge system was configured and how we measured quoting latency. Next, we present and briefly discuss our benchmark results. We conclude by discussing some of the lessons we learned in our pursuit of low-latency.
2 Benchmark Methodology
For our benchmark we opted for a quoting optimized hardware configuration. We dedicated a Dell R330, running Ubuntu 14.04 and version 3.19.0 of the Linux kernel to the BTS Quoter and used a separate machine to host the less latency sensitive portions of the BTS Edge system. The R330 has only four cores on its single socket Intel(R) Xeon(R) E3-1270 v5 but these cores are faster than what typically is found on higher core count CPUs. This results in a fast but relatively inexpensive quoting platform, a trait we can exploit to accelerate our quoting in a cost effective manner.
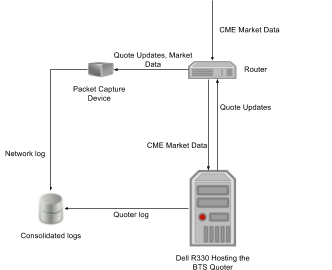
We configured our BTS Quoter host to receive multicast CME market data and stream quotes through a 10GB Solarflare SFC9120 NIC which we used through the Solarflare Onboard kernel bypass drivers. In order to measure true wire-to -wire times we attached a packet capture device to our router. This device was able to log every network packet passing through the router, timestamping each message with a high precision timestamp. To facilitate correlation between market data messages and the corresponding quote updates, our Quoter marked each quote message with the sequence number of the market data message that triggered it. Using this information we were able to process the network logs produced by our capture device and compute a fairly precise measure of the total time it takes to turn a market data update into the corresponding quote update. We complemented this information with the BTS Quoter’s high precision logs so that we could isolate the time spent inside the BTS Quoter, that is the time elapsed from the moment the Operating System hands the BTS Quoter a market data update to the time the BTS Quoter hands the corresponding quote update message back to the Operating System for transmission. The diagram below illustrates our setup.
3 Results
A key goal for our test setup was to obtain measurements that would be representative of what our customers can expect to see in production. To that end, we configured our Quoter to maintain quotes on a variable number of high delta options on the CME ES Future and then simply let it run undisturbed for about 10 minutes against production CME market data. On a typical day the CME ES Future will change fast enough to trigger hundreds of quote updates, all of which we are able to capture though both our packet capture device and the BTS Quoter logs. From this information we extracted distributions for the total latency as well as the quoter only latency. To understand how the number of configured quotes affected overall latency we repeated the experiment for different quote quantities, starting at 8 quotes and ending at 1045. The following table summarizes our findings (all measurements are in Microseconds).
| Quoter Latency (μs) | Quoter + Operating System Latency (μs) | ||||||
|---|---|---|---|---|---|---|---|
| # Quotes | Median | 99%ile | StdDev | Median | 99%ile | StdDev | |
| 16 | 8 | 23 | 5 | 14 | 32 | 6 | |
| 32 | 12 | 25 | 5 | 20 | 33 | 6 | |
| 64 | 11 | 28 | 6 | 20 | 35 | 7 | |
| 128 | 13 | 31 | 5 | 20 | 40 | 6 | |
| 256 | 18 | 52 | 9 | 26 | 63 | 10 | |
| 512 | 28 | 46 | 7 | 38 | 56 | 8 | |
| 1024 | 36 | 83 | 12 | 45 | 91 | 12 | |
We were generally pleased with our results, though we believe we can still do better. Quoting options is a relatively complex process: for every underlier move the corresponding option theoreticals must be computed and a determination must be made as to what quotes need to be sent to the exchange. These quotes must then be encoded in the relatively inefficient FIX format. For a small number of quotes the BTS Quoter is able to do all of this in 8μs, though, of course, performance slowly degrades as the number of quotes increases.
4 Lessons Learned
In our quest for low latency we made a few mistakes and were forced to find our way out of the dead ends they lead us to. In the next sections we detail some of the lessons we learned along the way.4.1 Treat Performance as a Primary Design Driver
When we first started working in our quoter we followed common Software Engineering wisdom. We started with a top-level design that reused a number of pre-existing libraries and neatly separated concerns, using classical Object Oriented techniques to maximize extensibility and (we hoped) long term maintainability . We were quite pleased with ourselves right until we started to measure end-to-end performance - at which point the fancy abstractions and helpful libraries were shown to impose unacceptable performance penalties. Simply put, the numbers were not there, and we found it next to impossible to improve them beyond a certain limit. The painful conclusion was that the common adage “first make it work, then make it right, then make it fast”, did not apply when pursuing uncommonly low latency. Performance could not be bolted on top of a working design, it had to drive the entire design process from the start. Armed with what in retrospect should have been a fairly obvious insight, we started over, opting for a first principles approach. We started by asking some basic questions. What information did we need to generate a quote update message? How fast could we generate this message given that information? How much CPU cache footprint would that information take? How much work could be reused from message to message? We built a few prototypes to answer these questions and from the information they provided we were able to derive hard constraints that greatly reduced our design space. We then proceeded to add functionality incrementally, checking performance along each step. This bottom up, data-driven approach produced a very different design than what we started with but it also lead us to first meet and later exceed our performance targets.4.2 Measure Realistically
As mentioned we found early measurements essential to guide our work. But not all measurements are created equal. Early on in a project, only small individual components can be measured, typically using fake data and in an isolated setting. While these micro-benchmarks are useful, particularly in fine-tuning the inner loop algorithms used in the system, they provide only limited insight into the performance one can expect in production. In the real world caches are not always warm, interrupts happen at the most inconvenient times and data rates are wildly variable, so it is essential to set up end to end performance test cases as early as possible. Though we were aware of this fact and thus implemented end-to-end measurements as soon as we had a bare bones system, we made the initial mistake of using a low fidelity market data simulator to drive our quoter. Unfortunately this simulator produced messaging patterns that were not realistic and which hid some limitations of our design. Switching to a realist market data source immediately uncovered some of these issues. The lesson was clear: test in an environment that mimics production as accurately as possible.4.3 Cultivate Mechanical Sympathy
The term mechanical sympathy originated in race car driving and was brought to the software world by Martin Thomson, one of the designers of the CME MDP3 standard. The term is used to express the idea that in order to obtain the the best performance out of a machine, be it a race car or a modern CPU, one has to to understand the basics of how the machine works. The complexity of modern CPUs might make this goal look untenable at first but what we found is that even a basic knowledge of some of the key mechanisms goes a long way when writing fast code. These mechanisms include:- The cache hierarchy. Modern processors can execute hundreds of instructions in the time it takes to read a single byte from main memory. To hide this latency CPUs are equipped with a cache hierarchy: a set of very fast but relatively small memory circuits, each representing a different tradeoff between memory and size. To achieve good performance it is essential to carefully optimize the use of these caches, typically by using compact, cache-friendly data structures and minimizing context switches. The code that results from these practices is often counter-intuitive, particularly for those Engineers with a more formal Computer Science background. Many data-structures that make perfect sense in a textbook (or in a standard library), tried and true classics like linked-lists, hash tables or binary trees, perform much worse than the humble array in certain contexts, precisely because they do not take the caching hierarchy in consideration. In our quoter work we often obtained significant improvements simply by exchanging maps and hash tables lookups for linear searches over flat arrays.
- The branch predictor. Intel processors have supported superscalar operation since the introduction of the first Pentium in the early 90’s. This capability allowed CPUs to execute multiple instructions simultaneously, potentially greatly improving CPU throughput, i.e. the number of instructions executed per unit of time. However, this technique can only work effectively if the CPU is able to effectively predict the execution stream. Branching instructions, such as if-then-else statements, introduce forks in this instruction stream that can cause the instruction pipeline to stall until the outcome of the branch instruction is known. To keep the instruction pipeline humming CPUs will speculate; that is take a bet, on the outcome of a branch instruction. The circuits responsible for these bets are called branch predictors and they work by keeping a history of branching outcomes and looking for patterns that can help them guess more effectively. The upshot of all of this for the low latency developer is that is that a) branches should be avoided whenever possible and b) if they cannot be avoided then they should be reasonably predictable, i.e. one of the outcomes should be considerably more likely than the other. In our quoter work we saw the effect of helping the branch predictor first hand when we were able to improve our quote update performance by almost 20% by simply iterating over pending quotes in order of their deltas. Quotes with high delta are more likely to require updates when the underlier moves and by just clustering similar deltas together we improved the predictably of the branch that controlled whether a quote should be updated or not.
- The hardware prefetcher. Even with carefully memory optimized data structures, for some problem size an application’s working set, i.e. the information commonly referenced by the application, will grow too large to be held in cache. Modern processors address this issue though hardware pre-fetching. Prefetching units attempt to anticipate future memory reads and bring the necessary data into cache memory before the CPU actually uses it, thus avoiding cache misses and masking memory latency. They key, of course, is how accurate the prefetching algorithm is. If memory access patterns are complex, say, for example when traversing a linked list or a tree, the prefetcher might end up doing more harm than good, because most of its predictions, which are based on spacial locality, will be wrong and result in unhelpful cache evictions. Prefetchers work best when the memory access pattern consists of sequential reads with constant stride, which is precisely what you get when iterating over simple arrays. In our quoter work we found that even when working with a large number of quotes, we were able to avoid excessive cache misses by laying out the data required for quote updating in contiguous blocks. Even though sometimes this required a level of redundancy in our data structures, the performance gains were significant enough to warrant the extra bookkeeping.
Keeping just these relatively simple mechanisms in mind had a profound influence in the way we wrote the latency critical parts of our system. The resulting code was in some ways unusual - at least for those more used to Object Oriented designs - but the performance gains were substantial.
4.4 Control Scheduling to Reduce Jitter
Modern Operating systems such as Linux are heavily biased towards high-throughput often at the expense of latency. This becomes painfully obvious the moment one tries to run latency sensitive workloads using the typical out-of-the-box configuration for Linux. The result is almost always large inconsistencies from measurement to measurement: the exact same application transaction can take 10μs in one run and 100μs or even 1000μs times in the next, for no easily discernable reason. This large performance variability, commonly known as jitter, is one of the more frustrating challenges for the low latency Software Developer. Eliminating jitter is a black art, mostly consisting of identifying and defeating Software mechanisms put in place to ensure throughput and fairness. We found the following techniques particularly helpful on our war on jitter:
- Reserving CPU specific cores for our Applications. One of the main functions of the Operating System is to multiplex hundreds of processes onto a handful of actual CPU cores. The Operating System accomplishes this impressive feat by interleaving the execution of processes, i.e. by quickly alternating which process gets to use the CPU at a given time. This interleaving is mostly transparent to the application code but it can have a significant impact on the jitter of critical transactions: the kernel will happily preempt critical functions, such as anything in the tick to update path in our Quoter, with secondary activities. We can avoid this sort of problem by instructing the Operating System to avoid scheduling processes onto specific CPU cores unless explicitly told otherwise. On Linux the isolcpus kernel option can be used for this purpose.
- Routing interrupts away from reserved cores. By default Linux servers are typically configured to distribute interrupt handling between available cores. In latency sensitive workloads this can be undesirable as critical processes, even when running in reserved cores, might be preempted and forced to transition to kernel mode to handle a Hardware interrupt. This transition brings with it not just the direct cost of the interrupt handling code but also the indirect costs associated with data and instruction cache pollution. To further protect applications from preemption, and thus reduce jitter, we can instruct the kernel to avoid servicing interrupts through our reserved cores. On Linux this can be achieved by configuring the irqbalance daemon appropriately.
- Allocating each reserved core to a single high priority application thread. Our Quoter performs many concurrent operations: publishing diagnosis, responding to user controls, updating quoter parameters and so on. Most of these operations are not overly latency sensitive but a few are: market data handling, quote updating and FIX protocol handling. To reduce jitter we organized our critical functionality into separate threads, one thread per each of our reserved cores, and pinned each of those threads to a separate reserved CPU core. The non critical threads were then allowed free use of the remaining cores. To minimize synchronization delays we ensured our critical threads exchanged as little information as possible and always did so through lockless data-structures. This architecture reduced or eliminated several important sources of jitter: synchronization, context switches and cross context cache pollution.
Using these techniques, combined with sympathetic use of the CPU, that is avoiding caches misses and branch prediction failures, we were able to greatly reduce the jitter associated with our quote update timings.
5 Conclusions and Future Work
Developing low-latency Software is a demanding activity that is best served with specific design, coding and testing guidelines - some of which go against conventional Software Engineering wisdom. In this article we detailed our experience with this type of work and some of the lessons we uncovered along the way. In the future we plan to investigate the performance of our Electronic Eye as well as look at the impact of different Hardware configuration choices on performance. We are always happy to hear from our future and current customers so drop us a line if you are interested in learning more about our continued efforts to reduce the latency of our electronic trading offerings.