By Kevin Darby
BTS recently embarked on a research project to examine the feasibility of leveraging machine learning strategies to augment the performance of popular futures execution algorithms. During the course of this blog series, we will examine common execution algorithm structure, work through how machine learning (ML) can improve performance, and test accepted ML methods as well as present the results of new methods as applied to futures trading.
The Drivers Behind Our ML Research
Over the last few months, BTS has brought our new futures trading system, BTS Spark online and into production. We are thrilled with the industry response. As we talked to customers about the product, we found demand for two main features—execution and spreading speed, and the ability to execute custom algorithms on that same low latency fabric.
During the course of our work, I got a chance to delve into some of the more popular execution algorithms in the futures space in order to vet assumptions about how our API should work. We wanted to make sure our API was flexible enough so that a reasonably experienced engineer would find it natural to add these 'algos’ to our system.
Around the time I was working with a customer on some of these algos, a friend of mine sent me a Google Deepmind paper detailing how they successfully trained a computer to play Atari—not by coding up the rules of Atari, but by using a process called Reinforcement Learning (RL). RL is a process by which an algorithm 'learns’ how to successfully navigate an environment by exploring a set of plausible actions over an observed state, all the while trying to maximize positive rewards and avoid negative.
Immediately after reading the paper, I knew we had to try to apply this to futures trading, and the concept of BTS Neural AlgosTM was born.
Precept: The Order Book
All futures trading is done through an order book. This ‘book’ is simply a collection of intentions—intent to purchase is called a ‘bid’ (in blue, below) and intent to sell is called an ‘ask’ or ‘offer’ (in red).
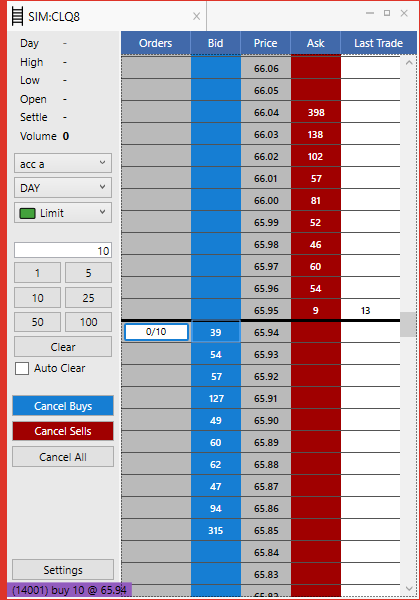
During the course of normal trading, bids and offers move around according to market conditions. When a bid and an offer occur at the same price, a match occurs and a trade happens. Bids and offers in the order book are often said to be ‘resting’, because they will not execute until a counterparty agrees to transact at the same price they’ve ‘posted.’ This general framework gives rise to a popular execution algorithm, usually called ‘Lean’.
Get your Lean On
Let’s say I want to buy 10 futures in the order book above. I have two choices:
- I can pay 65.95 to get filled immediately. This is like buy-it-now on Ebay.
- I can chose to ‘work’ a bid at 65.94 in hope that someone sells to me at my price before the offer of 65.95 increases or disappears. Note also that the existing bids already at 65.94 would have to be ‘filled’ before I get that chance.
The Lean algorithm, instead of simply paying the ‘buy it now’ price for the futures, tries first to bid to buy them slightly cheaper by waiting on the highest bid price. It then watches the size of the closest offer—if the size decreases below some pre-defined threshold, it ‘pays up’ and changes price to match to the offer price in hope that it does not ‘miss’ the offer and end up having to pay even more. Sometimes it works, sometimes it doesn’t.
That’s kind of like a game. One could (maybe) imagine a (much more boring) Atari game like that.
The Model
Most machine learning stuff is written in Python. Python is a weird language and its inventor (and benevolent dictator) recently abdicated. One really can’t be as effective with any other language, so you just sort of have to deal with Python.
A Reinforcement Learning setup starts with an ‘Environment,’ this environment tends to have physics, like a game. The environment here is the order book—and it has ‘physics,’ you can’t bid or offer in front of others who were there first. You can’t cancel other peoples’ orders. You must play fair.
The general learning method is to simulate thousands of trials through which the algorithm traverses (and sometimes searches) the environment, acting only within specified boundaries, in order to optimize ‘rewards’ given by the environment. This is easier said than done.
Partial Observability
The order book is only a view on reality. If we could observe the intent of every market participant, we could develop a policy through which we would compute the best action to take, based on the data.
However, we do not have access to the entire reality; the market data coming out of the exchange is only a partial observation of a deeper process.
So then, how do we model partial observability? Stay Tuned!
In the next post, we’ll begin to deal with the problem of partial observability, as well as examine the concepts of Stochastic and Deterministic Policy Functions, and walk through some generally accepted methods as we continue to research this fascinating and potentially game changing topic.